



最近AI界开源了一个TTS模型,掀起了很大的动静,Chat-TTS这个项目,当时第一时间就体验了,惊为天人,先听一段绘本故事:
下面结合今天的高考作文小试牛刀一下:
第一步,让chatgpt先写作文

第二步,把内容放到Chat-TTS里面生成音频
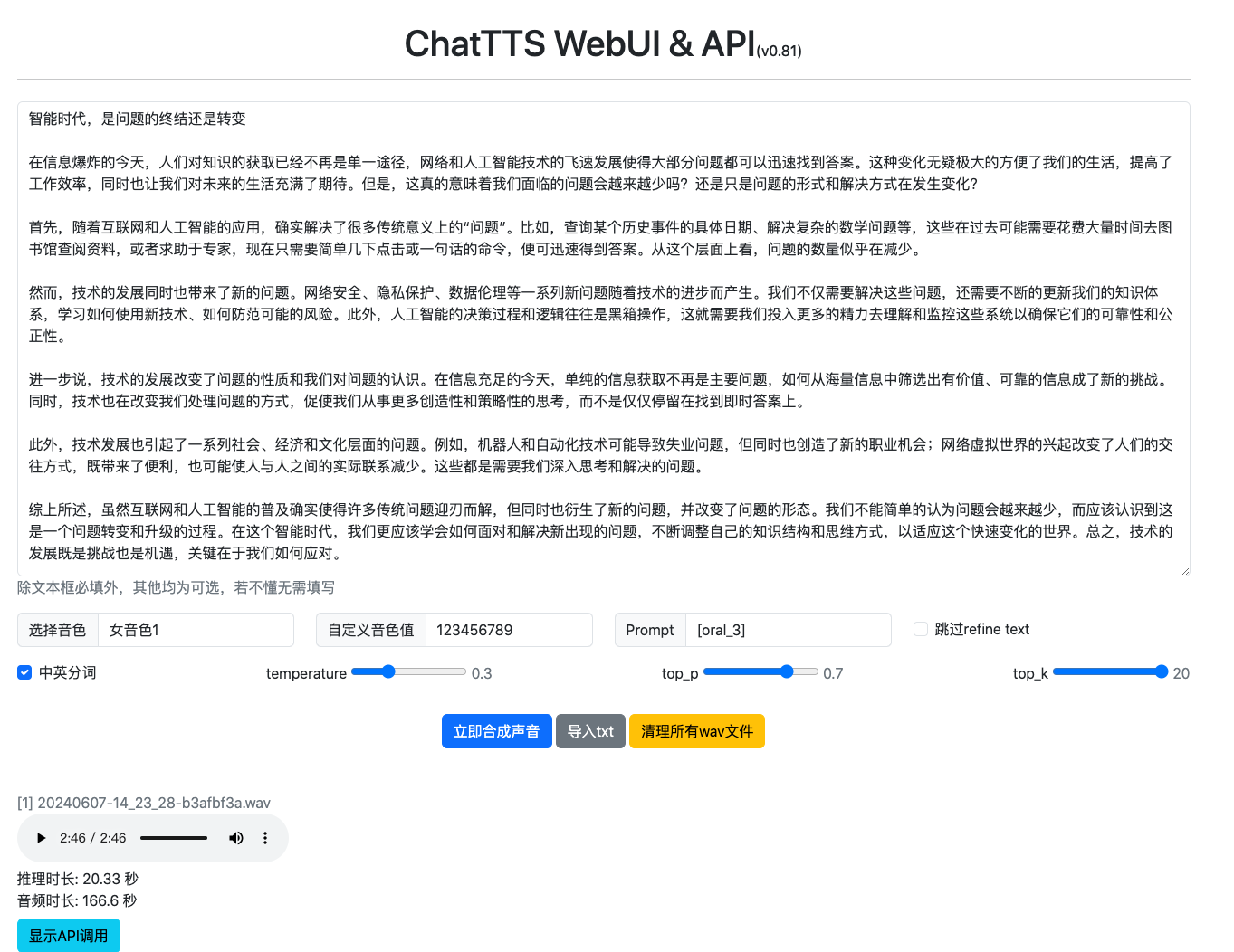
可以看到,生成速度非常的快,近3分钟的音频仅需20秒就生成了,下面把音频发出来听听效果
通过修改音色值(seed)可以生成不同音色的音频(类似于AI画图的抽卡),理论上是能抽出来任意音色的,后续也会有声音克隆之类的功能出来。
个人认为这个Chat-TTS的发布不亚于ChatGPT3的发布,以后接电话要谨慎了,虽然作者为了防止黑灰产恶意使用,故意在训练语料里做了一些手脚,但毕竟是开源项目,可操作的空间可就大了
字节最近也推出了seed-TTS项目,相当惊艳,地址如下:
https://bytedancespeech.github.io/seedtts_tech_report/
评论区